
What you missed about continues delivery
The focus of this blog post is on the crucial element of modern software delivery — continuous delivery (CD). In my experience, the larger…
The focus of this blog post is on the crucial element of modern software delivery — continuous delivery (CD). In my experience, the larger perspective of CD can be easily overlooked amidst scrum ceremonies and docker containers. This is particularly prevalent among smaller enterprises and startups.
Let’s explore essential practices for continuous delivery (CD) on different platforms.
- We’ll begin with web and cloud, which may not offer groundbreaking insights for CD practitioners, but it serves as an excellent warm-up before delving into more intricate platforms.
- Then, we’ll tackle mobile and desktop environments, including iOS, Android, and native desktop apps, which pose significant challenges for implementing CD.
- Next, we’ll examine some extraordinary applications of CD practices in Elon Musk’s companies, such as Tesla and SpaceX, for a more inspiring and aspirational perspective.
- Finally, stay tuned for an upcoming blog post, in which I’ll discuss my experience with continuous delivery in the blockchain space.
Web
Continuous delivery (CD) is most easily applied to web and cloud-based systems. The process typically begins with implementing continuous integration (CI), which involves building a new version of the system with each pull request using a CI server. This includes building the whole project with an entourage of various tests, linters, and checks to ensure the system is functioning correctly.
There are a few practices that accompany this: trunk development, automated testing, testing environments and automatic deployment. Let’s examine them one by one.
Trunk development
In trunk development, teams merge all pull requests (PRs) directly into the main branch on a daily basis, instead of long-lived branches that exist for days, weeks, or even months.
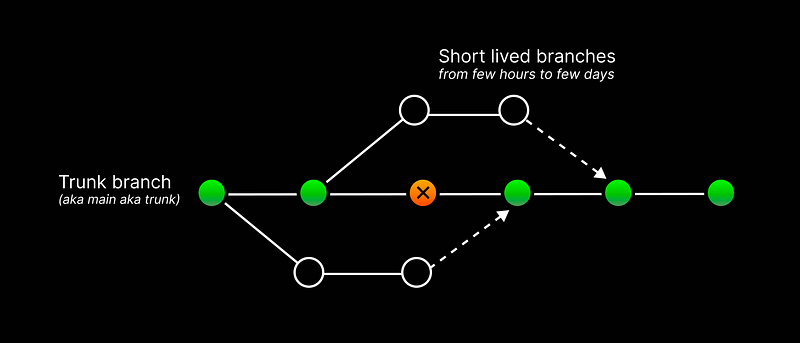 Trunk development
Trunk development
This approach ensures that there is almost always a stable version on the main branch, and the team can focus on evolving the codebase through small, incremental changes and refactorings rather than implementing large, complex features all at once. However, this requires the team to adopt a non-trivial skill of working with small commits and PRs, which may call for significant habit changes.
Automated testing
It is often said that automated testing is a crucial component of software delivery, and this sentiment should not be dismissed. Unit, integration, and end-to-end testing are all vital for deploying software with confidence directly to production. However, end-to-end testing can become more complex as teams work on different platforms. For a modern development team, it is reasonable to expect that the application logic will be extensively tested with unit tests, and that there will be sensible coverage of integration and/or end-to-end tests that emulate user interactions and trigger code throughout the technological stack.

The more static analysis that the compiler provides, the fewer tests are required to ensure confidence in the software. TypeScript, for example, provides an order of magnitude more confidence via static analysis than pure JavaScript, while Rust provides another order of magnitude more confidence via even more advanced static analysis than TypeScript.
Form staging to branch preview
To improve communication, collaboration with stakeholders, and manual testing, we would like to request a preview of the current working version. In the past, we relied on staging and testing environments that were updated regularly after a successful commit or periodically like once an hour. However, we can now offer an even better solution with a branch preview.

By deploying a complete environment for each pull request, we can make it available for testing before merging it into the main branch. Reviewers can easily test live code with realistic test data, while stakeholders can provide live feedback on daily work.
Setting up this type of environment is relatively simple. For instance, using Vercel + Supabase (or the more old-fashioned pair Netlify + Heroku if you prefer), a frontend and backend can be deployed after each commit for every pull request. Vercel will provide a GitHub link on the pull request that allows you to try out the current version. Alternatively, coolify.io offers a self-hosted solution or a skilled devops engineer can also set up the necessary infrastructure fairly quickly.
Automatic Deployment: Push on green
When you have confidence in your automatic tests and the comfort of a branch preview, you can consider using automatic deployment strategies such as “push on green”. With “push on green,” each commit to the main branch that passes automatic checks will automatically be deployed to production. It can be beneficial to establish a cadence and schedule deployments to occur at regular intervals, such as once an hour, day, or other specified time period.
This ensures that there is only one version of the software in production, and any changes made will be reflected in production swiftly.
Incremental rollout: Blue-Green and Canary
However, if you have a large system with millions of users, it may be risky to deploy multiple commits to all users without any live feedback from production. There are two popular strategies aiming to reduce risk and ensure a smooth transition between versions: Blue-Green and Canary deployments
Blue-Green Deployment uses two identical environments to switch traffic between them during the deployment process, without any downtime. This also adds the ability to quickly rollback to previous deployment, by switching the active server.
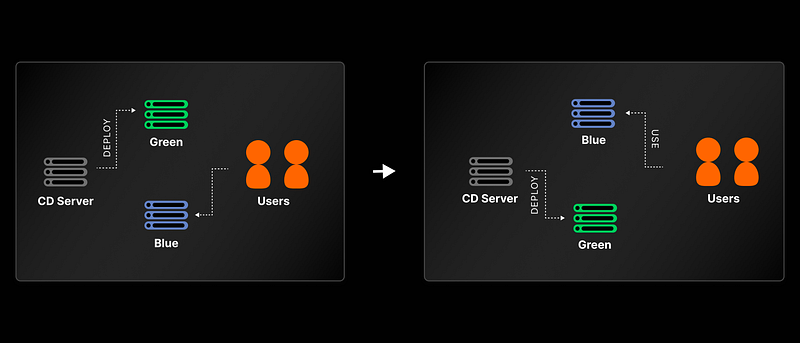 Blue-Green deployment
Blue-Green deployment
Canary Deployments are commonly utilized by larger teams as a means of gradually introducing a new version to a select group of users or servers.
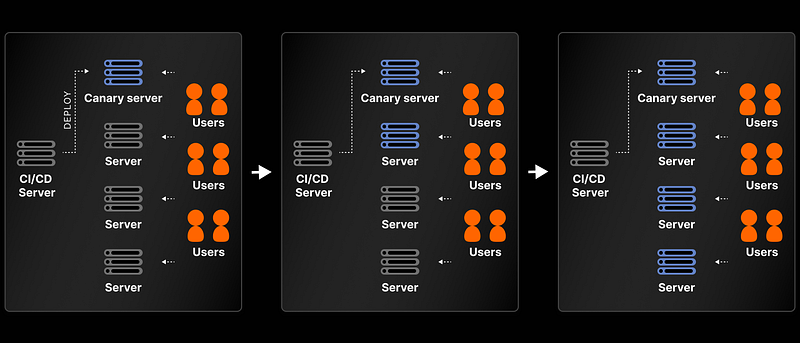 Incremental rollout — canary deployments
Incremental rollout — canary deployments
Both approaches help to mitigate risks and allow for careful monitoring and testing before making the new version available to a wider audience.
Impact
Frequent deployments create a fast feedback loop, which, when used effectively, can have numerous benefits:
- Firstly, it can make your users happier by providing them with frequent updates, bug fixes, and faster turnaround times.
- Secondly, it can make the job of the product team easier by providing live feedback from the working software, both on the branch preview and from users on production. A wider group of stakeholders can easily track progress.
- Lastly, frequent deployments can have a positive impact on the team’s performance and morale. As a wise friend of mine always says, “There is nothing better for an engineer’s morale than shipping.”
Now, it is all relatively simple and easy on the web. Let’s see what we can do on other platforms.

Mobile
The challenge
Delivering software on mobile platforms presents a challenge, as the deployment process must go through the App Store or Play Store, which can hinder the continuous delivery (CD) process. However, with the help of solutions pioneered by Big Tech companies, even smaller teams can navigate this obstacle and find ways to work around it.
Server driven UI
It is important to note that while there are various solutions available for CD, such as, server-driven UI used, among others, by Allegro. Smaller teams may struggle to leverage these techniques due to their limited capacity to develop their own technology. Therefore, we will focus on the Code Push approach.
Code Push This approach can be implemented using React Native. While many people believe that the main advantage of using React Native is the ability to code once and have the app available on multiple platforms, there are other benefits worth considering. For instance, mobile apps built using React Native can automatically upgrade on startup, enabling users to always launch the latest version of the app.
However, there are a couple of things to keep in mind.
Firstly, there are certain limitations on the kind of modifications that can be made to an iOS application to ensure that they do not violate the rules of the App Store. These modifications must not alter the intended purpose of the application or be harmful in any way. While Apple is aware of the technology and has informally accepted it, any misuse of this privilege could result in severe consequences, including the banning of your application from the store and the termination of your entire account.
Secondly, React Native architecture consists of a native part (written in native SDK) and a dynamic JavaScript part, and only the latter can be dynamically upgraded. The native part can only be upgraded via a slow store approval process. This is only necessary when an application wants to use new permissions or native capabilities of the phone.
It is worth exploring technologies that can construct and apply a diff, rather than downloading the entire new version, to reduce updates size.
Taking all of this into consideration, we can revisit the continuous delivery process for mobile platforms. Each new version will trigger two processes:
- upload to a server for mobile apps to download at launch
- submit to mobile stores to ensure that new users do not have to download the entire update every time they install the app.
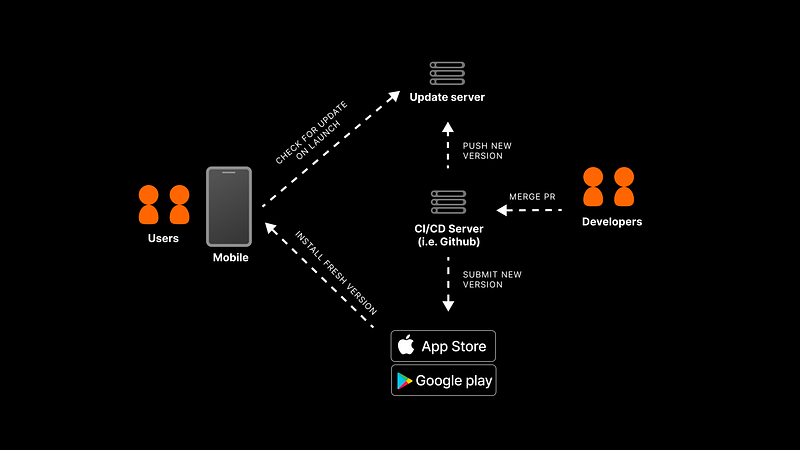 Code Push based delivery process
Code Push based delivery process
Tests
To ensure frequent and confident deployments on mobile devices, it is important to take testing to the next level. This involves setting up the entire environment for end-to-end (E2E) tests, allowing the simulation of clicking on the mobile device and interacting with all the elements of the stack, including the backend. Additionally, running these tests on farms simulating many device types is crucial for effective testing.
Monorepo and atomic changes
To maximize the advantages of continuous delivery (CD), a team can utilize a monorepo and atomic changes with a unified deployment process for frontend, backend, and mobile devices. This approach enables a single change to pass through all layers of the stack, promoting greater code sharing and facilitating the maintenance of a singular code version, which can be challenging in the context of mobile app development. One significant hurdle is API versioning, which we will discuss in the next section.
No API versioning
By implementing atomic changes, it is possible to forego the need for API versioning, as a single change can modify the backend API and all related clients (e.g., web, iOS, Android). However, it is important to maintain two versions, current and next, as releases can take time, and there may be users actively using the app during the backend upgrade. It is crucial to avoid disrupting their experience with untimely updates. Additionally, releases may fail, and it can take time to receive information about the cause of the failure, such as when it affects only certain types of devices. Therefore, it is necessary to have the ability to roll back releases.
 Simplified Mobile API versioning with CD
Simplified Mobile API versioning with CD
Overall, this approach is significantly easier than managing multiple API versions for an extended period of time. It does introduce another consideration to keep in mind.
Rollbacks
As the deployment process becomes more complex, it becomes increasingly important to incorporate a new type of automated tests that execute essential paths in production to ensure that the latest deployment has not been compromised. If a failure is detected, the system should automatically roll back to the previous version.
Other code push considerations
Here is an insight from a code push practitioner. There are two options available for updating React applications: IMMEDIATE and ON_APP_RESUME.
The IMMEDIATE strategy updates the app as soon as the JS bundle is downloaded. While this ensures that users always have the latest version, it may interrupt any process that the user is currently engaged in, which can be leveraged in case of emergency updates.
The ON_APP_RESUME strategy is more cautious, downloading the JS bundle in the background and waiting for the app to go to the background or be restarted before updating. However, this approach can still be ineffective for changes that pertain to early stages of the user flow, such as onboarding, since users are unlikely to restart the app and begin the process anew. Therefore it is recommended to refrain from utilizing code push to implement modifications that pertain to crucial flows’ initial stages, such as onboarding.
Desktops and TVs
Note that the techniques and technologies discussed in this context are not limited to mobile devices but can be applied to other platforms as well. For example, the Chrome team pioneered these techniques for desktop platforms, and today, all modern browsers seamlessly download and update to the latest version every few days. Similarly, applications on TV sets may also follow a similar approach, though these days, they are primarily web applications.
Incremental rollout
When dealing with high complexity and a large number of devices at stake, it may be wise to adopt a less aggressive deployment cycle. Rather than updating after every single commit, the new version could be rolled out on a weekly basis. During this time, the current version can remain on the devices of early adopters.
That is a lot of work!
It seems like a complex setup and… It kind of is. However, it is a fundamental investment into team productivity and it will pay off. Like most infrastructural investments, it should not be done all at once, but step by step. It is worth considering spending 10% — 20% of team time and resources to continuously improve the process over time, starting where the benefits for the team productivity and business are the biggest and keep addressing the biggest pains, moving forward. Thankfully you don’t have to do all the heavy lifting yourself. If you want to get serious about CD on mobile, you might want to take a look at services like bitrise.io or appcenter.ms.
Now if you think Mobile is challenging, let’s move to yet another platform — cars and space rockets!
Cars, satellites and rockets
One could say — continuous delivery is fine toy for web and mobile, but not for real, serious applications managing hardware worth billions of dollars and where people’s lives are at stake. To counter that belief, let’s review some known facts about Tesla and SpaceX, known to develop life-critical software. We can recognize the same continuous delivery principles, which are not very different from what we’ve discussed so far, but pushed further than anywhere else I am aware of.
Advanced automatic testing, over the air updates and incremental rollout are a hallmark of Elon’s companies software practices. Let’s start with cars.
Tesla
Tesla cars are famous for their over-the-air software upgrades, which includes new functionalities, user interface improvements and auto-pilot updates. We know a lot about the autopilot, in particular from investors’ day Tesla holds.
We know, for example, that any new version of the autopilot (i.e., the neural network that drives a car) needs to go through an automatic test suite that emulates real-life situations. With a real HD stream of data coming from all the cameras and all other sensors. Each test emulates a few seconds of a drive. Tests include virtual environment and real life scenarios extracted from real situations downloaded from cars on the roads that were problematic in the past. This way, the autopilot avoids regressions. The test suite is ever growing and running after each “merge”, so I suspect requires significant investments.
We also know that Tesla builds their own hardware for both car and data centers to speed up the network learning and in turn accelerate the deployment cycle. They are both billion-dollars projects.
 Tesla dedicated computers with own processors: for car (top) and for computation center (bottom).
Tesla dedicated computers with own processors: for car (top) and for computation center (bottom).
We know that all Teslas run unstable next versions of autopilot software in the shadow mode, and its behavior is compared with either driver or stable autopilot moves, depending on who is driving. This provides both feedback on stability of the new version and new learning input for neural networks.
The latest experimental version of car software is often used by Tesla employees and Elon Musk himself, before being deployed to a wider group of beta testers.
A fascinating aspect to note is that Tesla utilizes two different strategies for Over-The-Air (OTA) updates. For routine updates that do not involve critical issues, a WiFi connection is required, despite the car having its own LTE interface for music streaming, maps, Netflix, and more. On the other hand, for critical updates like regulatory and security fixes, the updates are downloaded via LTE. This dual approach to upgrades is a common practice that is also prevalent in the blockchain industry.
Another fact worth noting is that Tesla employs telemetry to determine the usage of features implemented in their cars. In 2022, during supply chain difficulties, they made a controversial decision to remove lumbar support in the passenger seats of Model X and Y. This decision was based on the fact that telemetry data showed that barely anyone was utilizing this feature. However, this move was met with criticism from those who wished to use it.
Rockets and satellites
To effectively build software for rockets, spaceships and satellites, SpaceX first and foremost built advanced physics simulators, which allow it to test behavior of hardware during simulated maneuvers.
In particular, Falcon rockets are known to have a “testbed” that consist of hardware mock of engines, griffins and all other rocket devices and sensors. The whole flight is simulated before the over-the-air-update to the rocket is performed. SpaceX is known to do software upgrades up to the last hours before the flight.
Starlink satellites is my favorite example of incremental roll-out usage_._ Each new version is first deployed to a single satellite, to ensure proper functioning, and only later deployed to the entire fleet.
Seeing how serious these companies are about speed of software delivery makes me inspired and think we could do better as an industry.
Summary
The foundation of modern continuous delivery revolves around familiar principles such as deploying early and frequently, along with a substantial focus on testing and failsafe measures to ensure secure and confident deployment. However, putting these principles into practice can be challenging. Hopefully, this information inspires those who desire to enhance their team’s processes.
Keep an eye out for our upcoming blog post on continuous delivery in blockchain.
I would like to give a shout out to people who contributed to the blog post.
Thank you for providing detailed feedback: Wiktor Gworek, Sebastian Gębski and Gabor Wnuk.
Big thanks to Natalia Kirejczyk for design work as well as Basia Ocios for editorial work on the blog.
Comments
Loading comments…